Introduzione
Dopo i primi due articoli introduttivi in cui abbiamo mostrato le basi dell’ambiente di sviluppo e le novità introdotte dal framework, ci avventureremo ora nella creazione di una semplice applicazione in Node.js utilizzando il SAP CAP e gli strumenti che mette a disposizione. Partiremo dalla definizione del data model, vedremo le diverse possibilità messe a disposizione per gestire la persistenza dei dati e, infine, abbozzeremo una semplice user interface.
L’applicazione
La semplice applicazione che creeremo servirà a tenere traccia degli ipotetici dipendenti (prima entità del data model) di una ipotetica azienda, registrandone alcune semplici informazioni di base, tra cui il dipartimento a cui appartengono (seconda entità del data model). Non c’è ovviamente la pretesa di sviluppare qualcosa di realistico o particolarmente rifinito (ignorerò ad esempio tutte le – noiose 🙂 – tematiche relative a localizzazione e traduzione), ma l’intento è quello di introdurre diversi concetti riferiti a questo nuovo modello di sviluppo.
Inizializzazione del progetto
Apriamo il nostro workspace (io ne utilizzerò uno nuovo) e un nuovo terminale, assicurandoci di essere nella cartella projects
A questo punto, per inizializzare il progetto e installare le diverse dipendenze richieste, dovremo digitare alcuni comandi da terminale. Il primo è
cds init Dipendenti
Notiamo che il risultato di questo comando è la creazione di una cartella Dipedenti nel nostro workspace, con una serie di sottocartelle e file; ci è bastato quindi un semplice comando da terminale per creare lo “scheletro” della nostra applicazione. Spostiamoci a questo punto dentro la cartella che il sistema ha appena creato per noi col comando
cd Dipendenti
e digitiamo il comando
npm install
Npm è il package manager di Node.js, e il comando install serve ad installare le dipendenze e i moduli Node necessari per la nostra app.
Abbiamo a questo punto terminato la fase di inizializzazione del progetto (che, nella gran parte dei casi, sarà molto simile per qualunque applicazione Node.js based), e, se abbiamo fatto tutto correttamente, dovremmo trovarci con la cartella Dipendenti strutturata nel seguente modo:
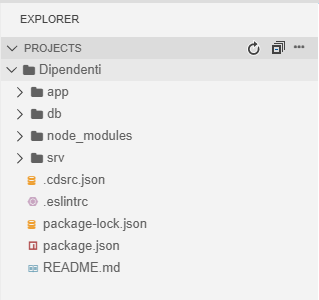
Le tre cartelle più importanti, che cds init ha creato per noi sono:
- app che conterrà gli oggetti necessari per la UI della nostra applicazione
- db che conterrà la definizione del data model del progetto ed eventuali file di appoggio
- srv che conterrà tutti i servizi definiti dalla app
Postilla finale: i nomi dei file che sceglieremo nel prosieguo dell’articolo non sono quasi mai casuali. Il framework si aspetta di default una certa nomenclatura e il fatto di soddisfarla consente sia di evitare una serie di attività di configurazione manuali piuttosto tediose sia di lavorare col maggior livello di automazione possibile, guadagnando quindi parecchio tempo.
Definizione del data model
Cominciamo ora con la definizione del modello dati del nostro progetto. Nell’introduzione abbiamo detto che sarà costituito da due entità: Dipendenti e Dipartimenti. Il framework si aspetta che lo schema del data model sia definito in un file schema.cds sotto la cartella db del progetto. Procediamo quindi col crearlo.
using { sap } from '@sap/cds/common';
entity Dipendenti {
key ID : Integer;
nome : String(100);
cognome : String(100);
ruolo: Ruolo;
dipartimento : Association to one Dipartimenti;
dataAss : Date;
salario : Decimal(5,0)
}
entity Dipartimenti {
key ID: Integer;
nome : String(50);
responsabile : Association to one Dipendenti;
}
type Ruolo : String enum {
Operaio; Impiegato; Manager;
}
Il file è piuttosto semplice, abbiamo definito due entità (Dipendenti e Dipartimenti), in relazione tra di loro (un Dipendente appartiene ad un Dipartimento e un Dipartimento ha un dipendente responsabile): la relazione è espressa tramite la keyword Associaton to. Abbiamo poi creato un tipo Ruolo in cui sono presenti i possibili valori per la proprietà ruolo della entity del Dipendente.
Creazione del servizio
Andiamo ora a definire un servizio con cui esporremo le due entità che abbiamo appena creato. Come abbiamo già visto negli articoli precedenti, i servizi vanno definiti tramite un file .cds sotto la cartella srv. Se necessario, l’handler del servizio va invece inserito in un file javascript con lo stesso nome del file .cds che contiene la definizione.
Creiamo un file Servizio.cds sotto la cartella srv del progetto e inseriamo le seguenti righe:
using { Dipartimenti as DipaModel, Dipendenti as DipeModel } from '../db/schema';
service DipService {
entity Dipendenti as projection on DipeModel;
entity Dipartimenti as projection on DipaModel;
}
Stiamo quindi dichiarando che il servizio esporrà due entity (Dipedenti e Dipartimenti) che saranno una proiezione delle rispettive entity definite nel data model (alle quali, nella definizione del servizio, ci riferiamo come DipaModel e DipeModel).
Se ora digitiamo da terminale il comando
cds watch
e apriamo il browser all’indirizzo che ci viene indicato, osserviamo che effettivamente la nostra applicazione sta già esponendo i due servizi che abbiamo da poco definito
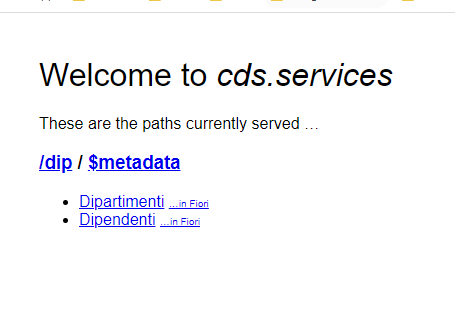
Cliccando sui due link al momento otteniamo una risposta vuota, non avendo ancora definito alcuna connessione a file di dati / database.
Creiamo dei dati di esempio
Una delle caratteristiche più comode del framework CAP è che il comando cds watch, oltre a ricaricare automaticamente l’applicazione ad ogni modifica dei file sorgenti, esegue in contemporanea un’istanza del tool SQLite, un leggero database in memory (ma vedremo che può essere configurato anche per persistere i dati su un file), che sostanzialmente funge da sostituto (mock) per il database reale che l’applicazione utilizzerà poi in produzione. Questo permette di velocizzare notevolmente i tempi di sviluppo e test dell’applicazione.
Come aggiungere qualche dato di esempio ? Creiamo una sottocartella data sotto db e aggiungiamo due file csv con separatore “;”, Dipendenti.csv e Dipartimenti.csv. Li allego per comodità.
L’unico aspetto da tenere in considerazione a proposito di questi due file è che i nomi delle colonne che puntano ad un’ associazione hanno il suffisso _ID e contengono appunto l’ID del record dell’altra entità a cui sono collegate.
Non appena salviamo i due file possiamo immediatamente notare che il terminale su cui abbiamo avviato cds watch si aggiorna col seguente testo:

Avendo chiamato i file come le entities, il sistema in automatico “abbina” i due oggetti e li rende disponibili al processo di SQLite. Se ora proviamo ad aprire il browser all’url a cui sono esposti i servizi e a cliccare sui due link, vedremo che i contenuti del file ci vengono restituiti (in JSON).

Operazioni CRUD e request
Notiamo che il servizio che abbiamo creato supporta già out-of-the-box le operazioni CRUD (create-read-update-delete). Possiamo facilmente convincercene utilizzando un’altra comoda funzionalità messa a disposizione dall’Applications Studio: un piccolo client REST integrato nell’ambiente.
Creiamo un file postDipendente.http (io in genere li salvo sotto un’apposita cartella test), e inseriamoci il corpo della nostra POST request (le POST servono ad aggiungere nuovi record)
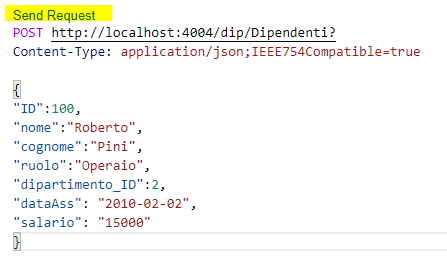
Cliccando su Send Request la richiesta viene inviata e possiamo vedere il response del server nel riquadro di destra
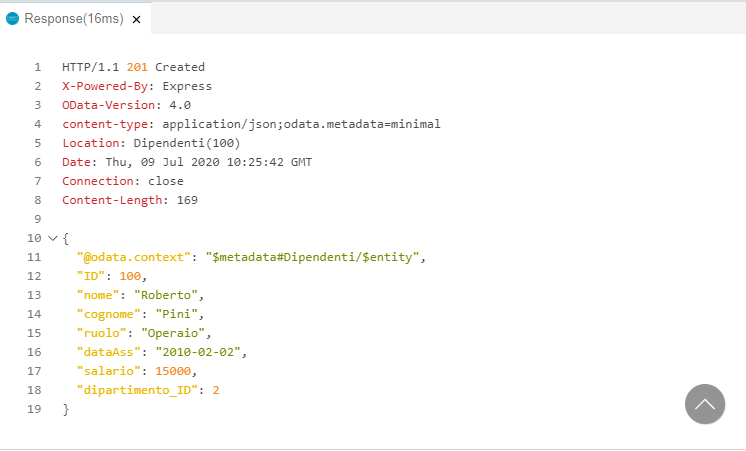
Per avere la conferma che tutto abbia funzionato correttamente possiamo provare con una request di tipo GET al path /Dipendenti (che è l’equivalente di quello che succede sul browser quando navighiamo sul link Dipendenti). Creiamo un file getDipendenti.http, inseriamo la nostra request e clicchiamo su Send Request:

La response, tra le altre entry (quelle presenti nel file csv), contiene ora anche quella inviata tramite la richiesta POST di poco fa:

Ricordiamo che stiamo lavorando in-memory. Ciò significa che se chiudiamo il Business Application Studio (o, ancora più banalmente, stoppiamo cds watch con CTRL+C e lo riavviamo, ridigitando a terminale cds watch), perdiamo il dato inserito con la richiesta POST, il quale è rimasto solo per il tempo di esistenza del precedente processo SQLite partito insieme al primo cds watch. Non perdiamo invece quanto contenuto nei file .csv, che vengono ricaricati in memoria ogni volta da SQLite.
Come fare in modo che i dati persistano tra una sessione e l’altra di sviluppo senza doverci complicare la vita collegandoci a un database esterno ? Fortunatamente la procedura è semplice e richiede solo l’installazione di un modulo SQLite aggiuntivo e l’esecuzione di un comando da terminale.
Iniziamo installando il modulo SQLite 3 e aggiungendolo alle dipendenze di sviluppo digitando a terminale
npm add sqlite3 -D
Ora è sufficiente informare il framework che vogliamo che il nostro modello cds venga deployato su un file database e non in-memory. Digitiamo dunque
cds deploy --to sqlite:database.db
Il comando crea un database SQLite nel file database.db; i contenuti dei file .csv di esempio vengono a loro volta aggiunti automaticamente. Essendo il database salvato sul file-system locale, esso verrà persistito tra le varie sessioni di sviluppo.
E’ tutto per il momento, al prossimo articolo !